Dragan Espenschied | Wed Oct 22nd, 12:41 p.m.
This is a mixture of manuscript and transcript of my keynote/closing lecture at Digital Preservation 2014, July 23rd in Washington, DC, held by the Library of Congress.
Big Data, Little Narration
Thanks for having me here—I am feeling really honored since I just arrived in the US in April, and now I am already here, at the Library of Congress.
This really is the land of opportunity. 🇺🇸
😄
My background actually is as an electronic musician and internet artist; I am not a trained librarian or archivist. However, my artistic work, which I do together with net art pioneer Olia Lialina most of the time, is very much concerned with how to write a history for the digital, networked age. This is because I think digital culture has certain properties that require us to ask how to historicize it, and not as much what.
I moved to New York to lead Rhizome’s Digital Conservation program, taking care of the Artbase.
Rhizome is a non-profit supporting digital art and digital culture. The organization was founded in 1996 by and for the internet art community.
The Artbase was started 1999 and is (I wrote it down here) “a collection of born digital artifacts in a user generated archive,” and I recognize there some traits of “archival futurism” (Sven Spieker).
Everybody could become an artist by uploading their artworks to the Artbase, there was only one, very low entry barrier: it had to be new media art. This is real digital culture: very fluid, the roles can change any time, and you don’t need a history to participate.
In the meantime, as correctly stated in the 2011 report by Ben Fino-Radin, who worked for Rhizome at that point, the Artbase has become an “archive of historic media art.”
This can be said about many utopian archives that were created during that time.
The Artbase is now a heavily curated place—with introductions, categories—as if all of it happened in the past, which it did.
But I wonder how this happened, how the “base” became an “archive,” grew stale and became something “historic.” I don’t want to say this is bad, I’m just wondering; after all, it shares this trajectory with many others.
My current thinking is that the answer rests in how such art collections are commonly thought about on the level of operations; that they turn historic when the artifacts that should be stored don’t follow the object logic anymore, to a degree that they do stop making sense inside the archive, or the archive stops making sense for them.
So allow me to follow this perspective of digital culture a bit. Let me also state that when we talk about edge cases at these conferences we say: “Oh, this is great, these are just edge-cases, after all this is art.” But I think that the difference between art and how general users are acting and expressing themselves on the web is absolutely blurry. And that is why what I say might be interesting to you.
I want to start with this stupid image:
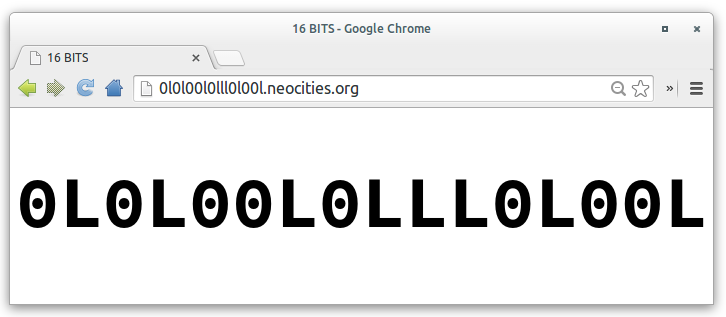
😁
😄😄
This is a representation of 16 bits. It uses the notation O and L, which I saw in a late 1960’s introductory manual to computer science from Siemens.

So what’s up with these guys, don’t they know zeroes and ones?!
But there are no zeroes and ones.
When we say 0 and 1 we are already talking about numbers. However, 0 and 1 are just two different symbols. And the reason that there are two is because this is the simplest possible distinction: two different things.
We don’t know what these bits represent, they could be an integer, a float, they could be noted in little endian, big endian, they could be some letter in some encoding, they could be a pixel RGB, RGBA, grayscale, whatever. They could be an audio sample, signed or unsigned. They could be a processor instruction that actually tells the CPU to do something.
And these roles can be assigned arbitrarily.
Each data point needs additional data about itself, stored somewhere else, describing what is supposed to happen with this data. Then, depending on how the machine operates on these bits, they move towards different meanings.
This is why I think it is productive to say: Everything inside the computer is a performance.
These performances are based on invented roles and narrations and expectations, already at play on this primitive level. The terms performance (what computers do) and activity (what users do) are helpful for thinking about preserving digital culture and its unique properties.
To illustrate this, I want to quickly show a very popular and very authoritative example of an “archive” or “data” and how it is accessed.
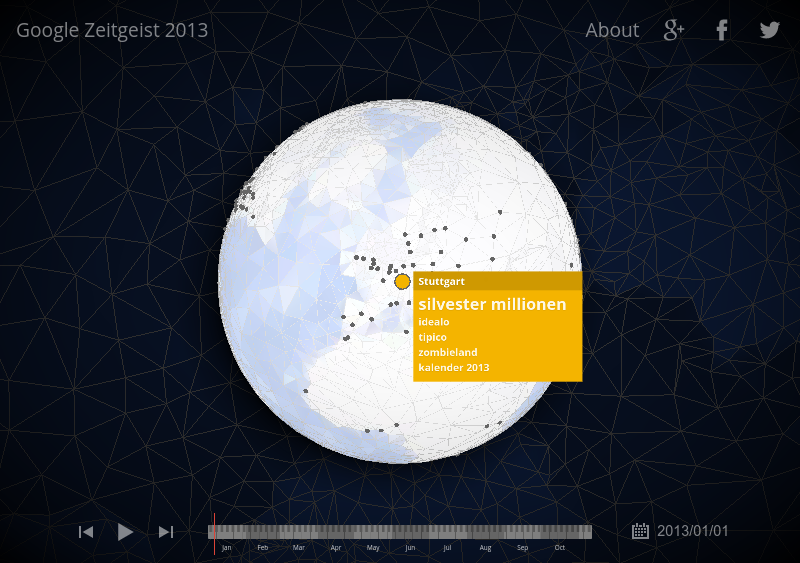
… going to Google’s Zeitgeist globe here …

This is a very nice thing. Stuttgart is the town in Germany where I am from. And this website apparently shows what users were searching for—what was on users’ minds rather—on New Year’s Day 2013.
(Google created an attractive visualization, so I can turn this globe here and then something in the back will also turn, which is very exciting. 🚨)
Let’s see what was up in my town: silvester, millionen, idealo, kalender, …
Let’s compare it with Berlin. Where is Berlin?
It’s difficult to …
Here it is.
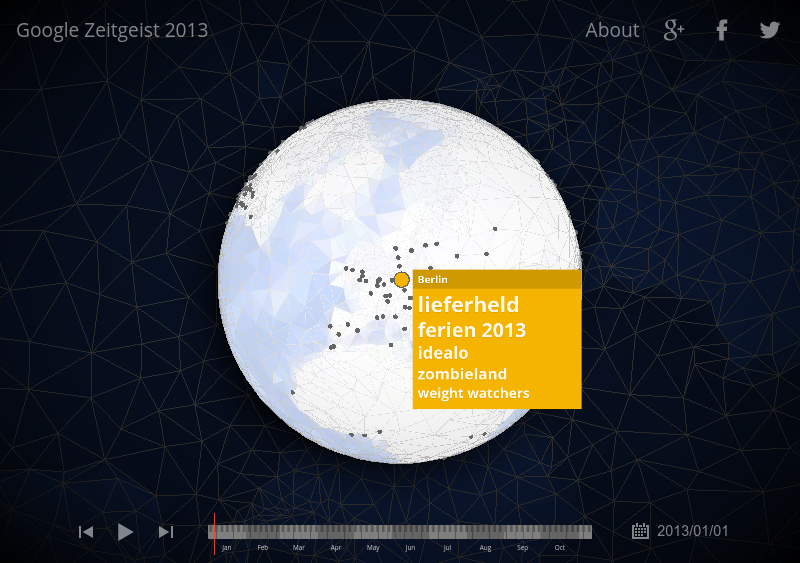
In Berlin, on New Year’s Day, we find Lieferheld. This is a German service like Seamless in the US.
🍕😄
What does this tell us?
Of course Stuttgart is this very conservative town, where engineers sweep the sidewalks every day if they are not busy constructing Mercedes; no wonder when they think about the next year, money and calendars come to their minds.
In Berlin live all these young, crazy, artistic people that just partied all night and need to order some take out food—because, unlike the inhabitants of Stuttgart who bought a calendar and planned ahead, their fridges are empty.
😄😄
But—what i just told you is completely made up.
I just pulled this out of my nose.
😄😄😆😄😄😄
However, it makes a very nice story, and next to this story I show a visualization of a globe, so it probably means that this data was recorded by satellites, by NASA, and it must be totally authentic.
😄😃😆😄 😄😄😃😄 😃
What we should really be asking is:
Why are these words grouped into cities and not to other words?
Why am I spinning this globe when in fact users were typing this into a search field?
And: where are all the sex-related searches?
😄😄
Lack of sex-related searches suggest an edit data set #digpres14
— Sibyl Schaefer (@archivelle) July 23, 2014This globe is making use of another cool thing that computers can do, on a higher level than the bits: creating arbitrary relations.
As long as any data set has a primary key, which makes sure every record is unique, and a foreign key, which makes sure it can be linked with some other data set, then I can tell any kind of story with it, depending on how many “hops” I am accepting from one dataset to another.
Why then Google use exactly a globe?
Let’s spin it a bit to give the engineers some credit. 🌍🌎🌏👋
😃😄😃
Well, as it happens, Google already has a lot of spatial data in order to show points of interest on their maps service; and they also have a calendar—I don’t mean the Google calendar service, but they have information about time and how it passes.
Then they have all these searches for which they record a place and time when they occur. And what to do with all of this? Of course, nothing else can come from it but this globe…
😄😄
…with dots on its surface and a time slider. Nothing we see here as Zeitgeist is a lie, but it is kind of meaningless or just missing the point. I strongly believe that archives of digital culture need lots of context and interpretation to fulfill their most basic function, but the kind of context is crucial.
What was really happening on New Years’ Day is probably this: …
what shall I ….
… do with my life …

😄😃
Why is Sonic the Hedgehog …
… so fast?
😆😄😺
.@despens asking the hard questions #digpres14 pic.twitter.com/XtVIoKjpSJ
— Ben Fino-Radin (@benfinoradin) July 23, 2014Google’s own autocompleter provides an interface for this archive of searches that narrates, that is powerful, that is also very close to the activities and performances on said New Years’ Day.
I am typing, and all these supercomputers are calculating or map-reducing away, and something very similar happened on new years’ day.
Maybe you are familiar with the culture that formed around this autocompleter, there are lots of users making screenshots of the funniest things they can find there. The autocompleter has become a present day oracle.
And nobody makes screenshots of the globe.
😄😄
The data in the autocompleter is kind of representing itself. It doesn’t need any highly developed visual aid or new form.
Of course this features is technically super sophisticated—but these are just the searches, and they are freed from a constraint of space and time because they are not linked to anything but their own kind. Users can capture an overview via their own exploratory work. (It also proves that sufficient speed of access can counter a lack of useful metadata.)
The searches on the globe are locked up in space and time. I can’t do anything with them anymore and I won’t make a screenshot of them because this globe is so lame.
😄
I don’t want to bash Google or anything, but it just seems that these decisions come so naturally: putting things on a globe, on “the world.”
When it comes to the idea of activity, this globe subordinates the users’ activity and focuses on the activity of the database designer and ultimately the query, while the autocompleter gives access to recorded activities through similar activities.
Another example:
Since 2011 I have been, together with Olia Lialina, analyzing the Geocities Torrent.
I won’t give an introduction to this collection of amateur homepages, let’s just say for those who don’t know: Jason Scott was involved.
😄😄
Second time today that "@textfiles was involved" lovingly used in a presentation to elide a lot of hard work #digpres14
— Christie Peterson (@save4use) July 23, 2014We have 36 million files and roughly 1 TB of data, a gold mine of digital folklore and vernacular web culture. It hardly qualifies as big data, anybody using hadoop will laugh about us, but for two people it is quite a lot.
There is hardly any metadata attached to these files, so we aked, how can we get meaningful access to all of them?

When I show this graphic, a treemap visualization of www.geocities.com, it is usually very popular, and some people on the internet even called it more beautiful than Geocities was.
But beauty is not the point, because it has actually the same problems as the globe: introducing some order where there was no order.
I could run gdmap on my root file system and it would produce a similarly beautiful picture. As a tool to find restoration problems, to demonstrate, for example, where file duplicates or the hundreds of infinitely nested directories are located in the file system, it is helpful though. And there is not much more we know about these files than where they are located. There is even hardly any valid HTML in there. Instead, so much of it is hand made, typed in Microsoft Notepad, or made with weird graphical tools of that time, like FrontPage or Netscape Composer.
In 2013 I finished the Screenshot Factory, after two years of really painful restoration of the actual data. It accomplishes the following:
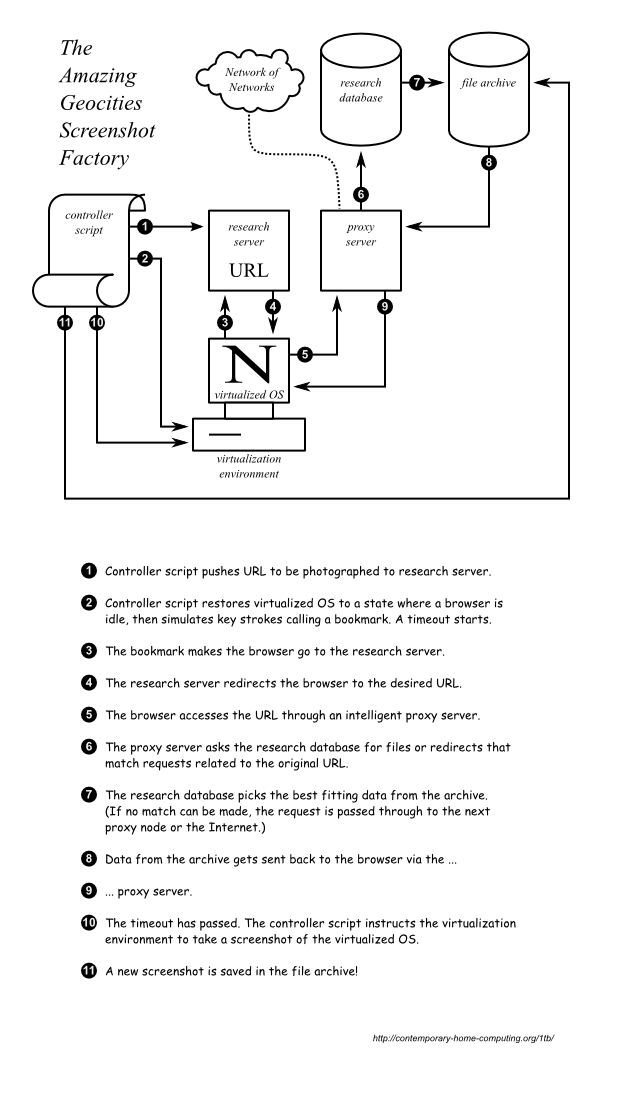
An emulator runs a legacy operating system and browser, surfing by itself through this restored version of Geocities home pages, starting in 1994, moving towards 2009, taking screenshots of all home pages on its way, and posting them to a tumblr.
Tumblr has a posting limit, so there is a new screenshot every 20 minutes. The Geocities torrent delivers material for 14 years of tumbling.
😄😄
It is actually a quite popular tumblr, approaching 14’000 subscribers. Currently we are in the late 1990’s, when Internet Explorer has overtaken Netscape. The screenshot factory keeps posting and posting.
Let’s look at the tumblr archive here, which again demonstrates that speed of access to material can in many cases counter a lack of metadata that would suggest another form of navigation.
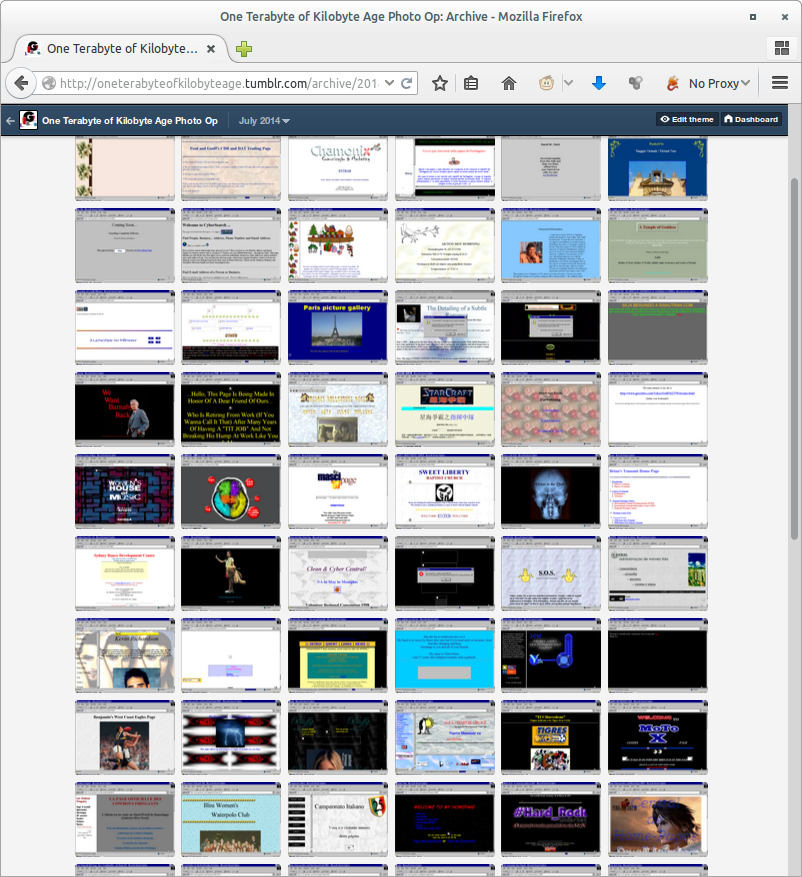
I can flip quickly through the “archive,” and if I have a trained eye—after all this time I acquired one, training on even faster access with the local copies of these images—I can immediately identify: oh there is an animation of Felix The Cat walking on a star background, that’s interesting.
😄😄
These are cultural forms, folkloristic expression that have a meaning. Olia and I are really into digital folklore and the vernacular web. Let me show you how these screenshots are designed, because in fact they are heavily staged.
At the moment we only see Internet Explorer, but I want to show Netscape.
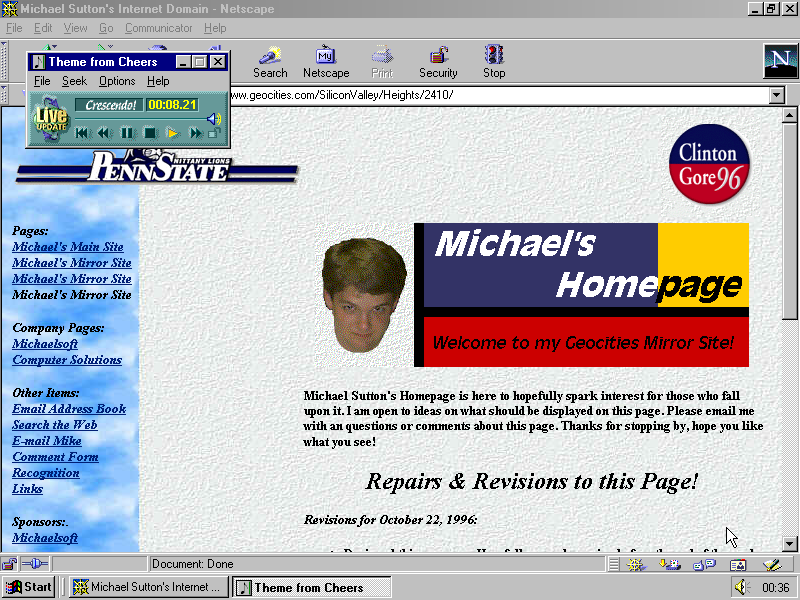
The browser is visible. The operating system is visble. This is not Windows 98, it is Windows 2000 which I configured to look like Windows 98. Hmm … 😒
Additionally, the web pages on display might have been created 1996. This very beautiful version of the Netscape browser didn’t even exist in 1996, but, I mean, it is… fine. I did a great job.
I also installed the “crescendo” plugin that replays background midi music in a floating pop up window, so the music is represented on the screenshot. I don’t know, I am not hung up about authenticity or anything, because anyway … I could browse these pages with Internet Explorer 11 and it would be authentic because I did it. But I sent a robot there to do it for me with Netscape 4.
"I'm not hung up on authenticity or anything… It's authentic because I did it." says Dragan. #digpres14
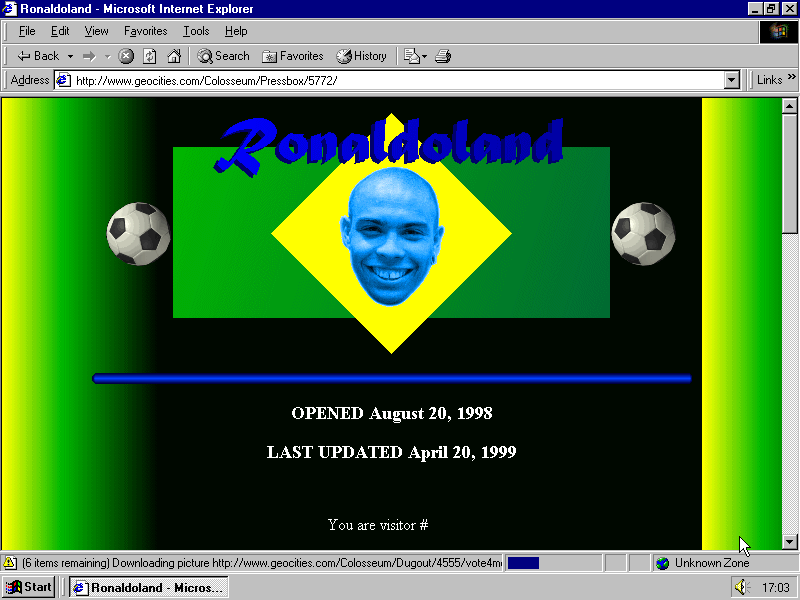
— Good,Form&Spectacle (@goodformand) July 23, 2014These images are made to look attractive and to be easily rebloggable, their size is 800×600. They shows the audience on tumblr a pre-industrial internet 🏭 that most of them have never seen because they are very young.
😄
For them it is really curious. They are interested in visual culture, this is why I chose tumblr as a publishing platform.
And they are “noting” the images like crazy, sometimes even an empty Netscape window gets lots of notes, because Netscape is just another generation of software that doesn’t try to be transparent; current software on the contrary tries to be so transparent that you don’t even notice it is there, that’s the current design style. Netscape instead screams: “Hey, look at me! I am the internet!”
😄
Kind words about @tumblr being said in discussion of One Terabyte of Kilobyte Age ❤️❤️❤️❤️ good to see the blog on a big screen #digpres14
— amanda brennan (@continuants) July 23, 2014Now, didn’t I make the same mistakes that I blamed Google for? Didn’t I also use arbitrary connections when staging these images like a theater play?
I think there are important differences:
I didn’t create an artificial context that prevents further user activity, but one that enables more user activity. 🔓 These screenshots are usable, these young folks on tumblr take them and recombine them with others, on their own tumblr blogs. Or they put in on Facebook and get more followers and friends.
Geocities pages were highly communicative, and now they can be used for communication again. These screenshots are not the end-product; rather they are more of an entrance portal to the actual story. The Zeitgeist globe is the End Point: “this year in search.” 🔒
And please also note that producing screenshots is not about taking apart the actual data. It is about re-staging a standardized computational performance, taking all these different files, putting them together into one representation and then making an undividable object out of them—a screenshot. This screenshot captures a record of user activities leading to the creation of this home page, and through that produces narration. (For example, if you look just at an isolated star background image, it doesn’t narrate at all.) And screenshots can survive in the current social media tempest, because they cannot be torn apart.
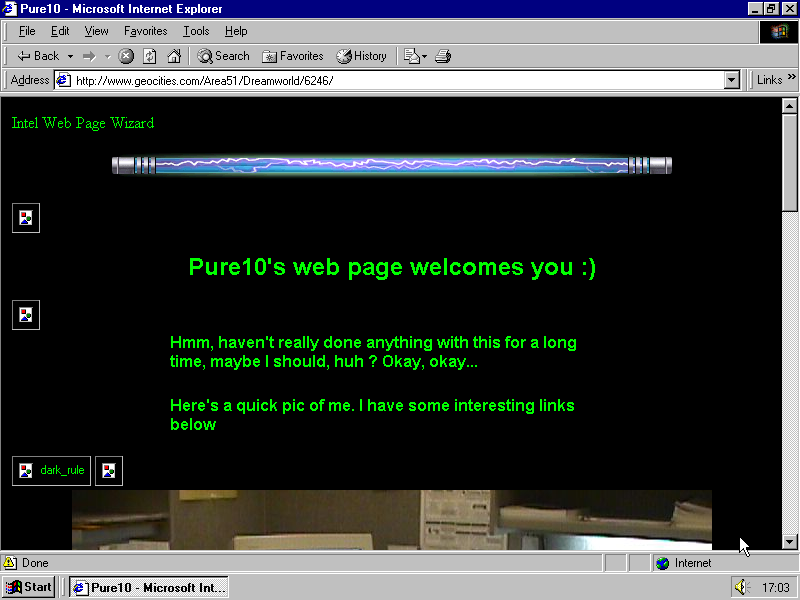
Now let me read to you what Olia wrote about the first page screenshotted in Internet Explorer:
One day in 1998, Pure10 moved into the Dreamworld suburb of the Area51 neighborhood, house #6246. He built his home page using Intel’s Web Page Wizard. He made index2.html with more pictures, and index3.html which tells more about him, and Index.html with “Possibly more stuff to come.”
In an attempt to modify the template he made quite some copy-paste mistakes and messed up the HTML syntax.
[…]
He added links to the Corrado Club of America, weather forecast for Pittsburgh, USA airways and stock market charts, then sent his files to the server for the last time.
I consider this history. This is user activity that can be understood from looking at an artifact that was re-assembled through a re-enactment of a standardized historic computer performance.
.@despens shows how interactive *aesthetics* become methodological, semantic - shaping data analysis, imposing meaning, narrating #digpres14
— Shannon Mattern (@shannonmattern) July 23, 2014A big part of my job at Rhizome is to figure out what interesting parts of this approach to conservation could be put into action as an institutional process, and trying to tap into resources that are more akin to oral history.
My perspective on digital art is really that this instability and variability is not a problem, it is just a thing that we have to deal with. We do not need to pin down artifacts into one single form, instead we need to conserve exactly these variable qualities.
On the other hand, things need to be in some kind of form, they need to exist on some banal level, in some “place,” and need to be referenceable. And then there is the sheer amount, the fact that every collection of digital culture is by definition too large for the institution that tries to handle it, because—it is digital culture. It would be injust to concentrate conservation efforts on a small selection of artifacts (like a museum), as this would fail to represent the fluidity of roles I mentioned earlier. And it is also not right to fall back to normalization and mass processing only (like a library), as this would fail to represent the wide, heterogeneous materials and processes. A position in between is needed.
I believe it is productive to move a bit towards trying to conserve the banal: standardized systems and environments that enable unique artifacts to perform and users to act. There is a way to do that with this catchily named Emulation as a Service project “bwFLA,” from the University of Freiburg in Germany. Rhizome is a research partner with them.
@despens making digital culture banal, is that archiving? #digpres14
— Abigail Potter (@opba) July 23, 2014So, environments in which these digital artifacts perform are quite standardized. And there needs to be a way of thinking about how these systems are built, one that is also activity based.
Look, this is quite different from just a screenshot:

😄😄😄 😆
MIDI files from Nightmare Before Christmas score in emulated archived geocities page in @despens #digpres14 talk
— Trevor Owens (@tjowens) July 23, 2014I don’t know what’s funny about this, this is digital culture. Nobody laughed about the globe. And the globe is actually funny.
😄😄😄😄😄😄😄
“I don’t know what’s so funny about this, this is digital culture.” @despens it is beautiful, amazing, wonderful, and hilarious. #digpres14
— Ruthless Killer Till (@ruthbrarian) July 23, 2014So how did I create this system that is showing legacy websites within their contemporaneous software, from the original URL? The main thing is to conceptually separate the artifact from the system that is enabling its performance.
We start with a standardized, off-the-shelf system, in this case Mac OS 9, and I would have to make certain alterations to it, maybe to change the screen resolution, turn up the sound, install a Quicktime plugin, or whatever. Each of these configuration steps is recorded automatically while I do it, as a difference to the base system image.
Like that, a dependency tree is created just via usage of the system. For instance, maybe some of you still remember the pain that you needed all this DropStuff™ and StuffIt™ expanders to get in fact anything to work on Macs.
So the first I make sure is that StuffIt™Expander® is on my system, so I can actually unpack the browser that I want. With the browser I download the legacy Flash plugin, and so forth. When I am done tweaking and my artifact performs as desired, I have created, as a side effect, an environment that is able to do lots of other things, to artifacts that fit the same class. Again, this is following the concept of recording activities and performances.
And if I am combining only software versions from a certain time period, it will provide relief from having to know too much about every single legacy artifact. Most of them will perform just fine combined with a typical environment from the time they were actively used. This is especially true for websites, CD-ROMs or any other broadly accessible artifacts. And if something more specialized is needed, it can be derived from a typical environment.
Isn’t that nice?
At Rhizome, we are thinking really about a stability of access and different forms of access: it could be a screenshot, it could be the website in the normal browser, it could be a website in an emulator.
An internet-based artwork will travel through all of these stages: for example it starts out on the artist’s server maybe, and if we’re lucky we get a copy for our archive. After some time it would move to be accessed via a contemporary client (browser) from our archive when the artist’s server is not working anymore. And then at one point it will have to flow into emulation of the client and the server, when it is not meaningful anymore to use contemporary clients with it.
All of these forms are totally valid.
But then there is still the problem of the “object boundary.”
Let’s look here at globalmove.us, which is one of these headache artworks, not because you get a headache from it, but because it is so unstable and difficult to conserve.
In its current form, you already see that the Google Maps service changed from when the piece was made, so much that it doesn’t show all the map tiles it should be showing.
The piece uses algorithmic graphics, it uses randomness to choose these marker icons, and it uses Google Maps. So how would I conserve that? I will just record what happens.
It works like this: here is the website, it is running in the browser and does all kinds of crazy things. Down here, it connects to a proxy—that was, BTW, part of a toolset created by Ilya Kreymer, who was very cooperative and willing to add some features that Rhizome needs. The proxy sees all the traffic, to the piece’s web server, to Google Maps, and everywhere else. It also inserts fake certificates to work with HTTPS, like a man-in-the-middle attack.
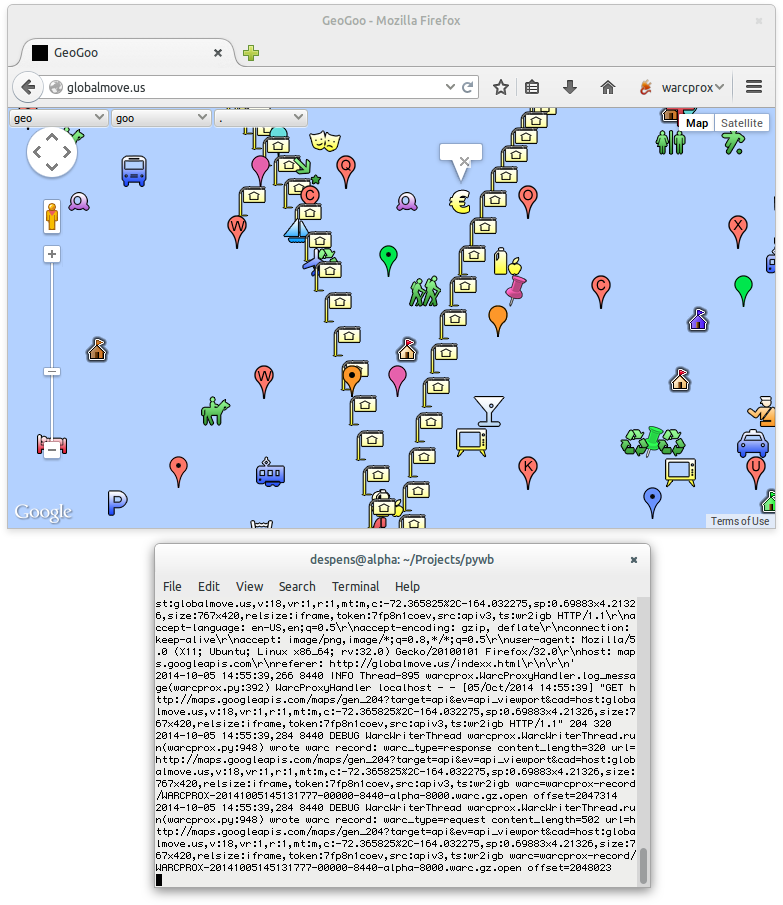
And if I wouldn’t have made a stupid mistake 💢💣💥 it would have recorded a warc file.—Well, we’re just starting out.
(As Matt Kelly later pointed out, nothing was recorded because the browser already had cached everything and didn’t request the data again from the network.—Shouldn’t have tried it out before!)
Via the recording approach, an object boundary is defined just by looking at the activities. If I would want to conserve this artwork, I would just go through all of the menus, look at everything manually, and what ends up in the recording represents the artwork.
OK, that’s what i wanted to show.
Thanks for having me. 😌
👏👏👏👏
👏👏👏
Time for some questions. Anybody has questions?
When you get the emulator running, will there be searching on Geocities? As a teen I built some Geocities sites. Well, I thought I was gonna ask … 😃
I get this question so often. 😄
Will I be able to search? I don’t remember the URL.
I didn’t create a search for it yet.
And I also don’t think that I want to publicly host it, because there are already other copies around that have been modified in some ways that I do not approve of, but the material is in general there.
Apart from that, you should be able to use the emulator, and listen to the Backstreet Boys MIDI file that you embedded into your page.
😄😃
It was Deep Space 9! Give me some cred!
😄😄 😃
😂 Deep Space 9! Nice! 🚀
We’ve spent a lot of time talking about accurate preservation, you’ve been talking about instability, changes, variability as potentially assets and not problems.
Do you want to talk a little about if you create something, you want to be able for someone to experience it later, in ten years from now, is accuracy important to you? How is this different in preservation?
As an exhibiting artist I drive curators up the wall, like if they use the wrong projector.
But this is a totally different situation. If I put something online, if it is really about internet art, what say do I have about what users are doing with that?
Maybe you remember these small graphics saying “watch this with Internet Explorer 5,” then, OK, I can’t. Shall I leave now? Should I buy a Windows computer with Internet Explorer 5? Of course I won’t, I will just continue.
It is kind of liberating having the Artbase that is essentially Internet Art. Sometimes it is critical to find out and to make a decision about for example what emulation environment we want to bring up exactly, shall we give a choice, shall we give this choice to the artist?
These questions exist because of the artifacts’ variability.
But if we would artificially fix these artifacts, it would really damage their authenticity.
I’d be curious for your take on different roles and responsibilities for different sorts of organizations.
In particular, this Geocities stuff is possible because Archive Team collected that and obviously there are other collections that existed in an archive.
Different organizations do web archiving for different purposes.
Are you in the position that you imagine sort of scholars or historians using these materials or creating interpretations of them?
So where do those lines in your mind come together and what different sorts of focus do you see in this space?
Something that has to be rethought are the roles of archiving and curating exhibitions.
All these artworks and in general digital artifacts need so much context to be understandable at all. It is not like I decide to hang one picture on this wall and another on this wall and it will make some nice combination in the white cube and speak for itself.
As I mentioned, there is an audience on the tumblr that has never ever seen the old web, let alone even used something like it. This happens so fast.
If you would sit some young person today in front of Windows 3.11, they wouldn’t be able to understand what’s up! They would say: Why are there windows in windows? 😲 What’s wrong?
😄😃😄😄😄
“Why are there windows in windows” is the perfect #digpres14 closing question.
— Jefferson Bailey (@jefferson_bail) July 23, 2014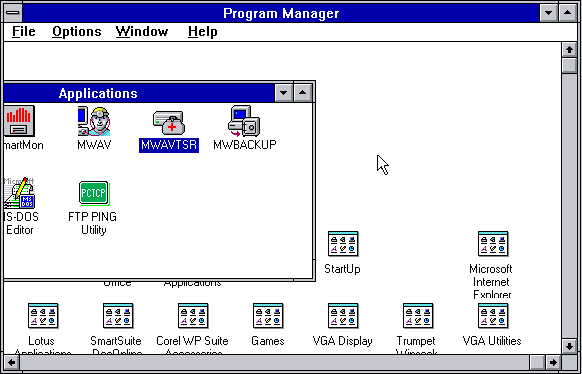
So I think that an archive of digital culture needs to provide much more context. And of course then decisions have to be made. As an archivist I totally see myself in the position to make these decisions and everybody else should do the same, because these are just different encounters with the same kind of thing.
Each of them is right and each of them is true.
In response to a q about different roles/responsibilities re: archives of digital culture, @despens making great case for artists #digpres14
— Trevor Munoz (@trevormunoz) July 23, 2014And of course: scholars, I love them. However, I think that scholars have a problem with the citation of such complex artifacts and encounters.
I can’t say, “I’ll just link to this url, and then you should click on this thing and then on that thing…” This is where emulation can help and this is what we’re working on, freezing an emulator in a certain state which is not time-based, and then be able to link to that state of the whole system.
I think scholars will really freak out about that.
⌛
👏 👏👏👏
👏👏
Many thanks to Mat Kelly who recorded almost all the conference talks!